
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
| 31 |
- 면접왕이형
- 베스트 모델
- 밑시딥2
- GPT-3
- 로지스틱 회귀법
- k겹 교차검증
- 뉴로 심볼릭
- 경사하강법
- 안드로이드 구조
- 모두의 딥러닝
- 과적합
- ESG 채권
- 안드로이드
- 코틀린
- 다중분류
- 보이스피싱
- ESG
- 독서 #독서후기 #피로사회 #행동과잉 #긍정과잉
- andoriod with kotlin
- 예측선
- 밑바닥부터 시작하는 딥러닝
- 밑시딥
- nlp
- 딥페이크
- 선형회귀
- 면접왕 이형
- MRC
- 학습 자동 중단
- 경제신문스크랩
- gradiant descent
- Today
- Total
Practice makes perfect!
Week 9 (4) 한국어 언어 모델 학습 및 다중 과제 튜닝 본문
1. BERT 언어 모델 기반의 두 문장 관계 분류
1) 두 문장 관계 분류 task
- 주어진 2개의 문장에 대해, 두 문장의 자연어 추론과 의미론적인 유사성을 측정하는 task
- 두 문장의 [CLS] 토큰에 classification layer를 부착시켜 두 문장의 관계 분류
2) 두 문장 관계 분류를 위한 데이터
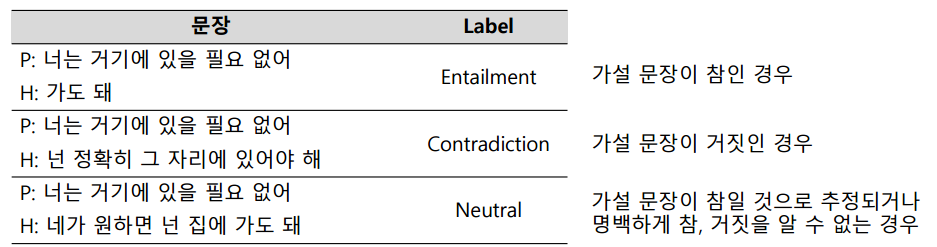
Natural Language Inference(NLI)
- 언어 모델이 자연어의 맥락을 이해할 수 있는지 검증하는 task
- 전제 문장(Premise)과 가설 문장(Hypothesis)을 Entailment(함의), Contradiction(모순), Neutral(중립)으로 분류 (3개의 label)
Semantic text pair
- 두 문장의 의미가 서로 같은 문장인지 검증하는 task (두개의 label)
2. 두 문장 관계 분류 모델 학습
1) Information Retrieval Question and Answering (IRQA)
- 사전에 정의해 놓은 Q/A set에서 가장 적절한 답변을 찾아내는 과정
- 이전에 [CLS] 토큰과 cosine 유사도를 이용해 챗봇을 개발했던 실습과 유사
- 질문 -> BERT를 통해 sentence embedding 수행
- 사전에 정의한 Q/A 테이블도 sentence embedding 수행
- 기존에 존재하던 데이터셋의 Q와 사용자 쿼리의 유사도를 비교해 가장 적절한 문장 반환
- Paraphrase Detection이라는 두 문장 관계분류 task를 학습한 모델을 부착 (질의한 쿼리와 사전에 정의된 Q가 실제로 유사한 의미를 가지고 있는지 검증하기 위해)
3. BERT 언어 모델 기반의 문장 토큰 분류
1) 문장 토큰 관계 분류 task
- 주어진 문장의 각 token이 어떤 범주에 속하는지 분류하는 task

- 기존 단일 문장 분류나 두 문장 관계 분류의 경우 [CLS] 토큰 하나를 분류하는 task 였음.
- 토큰 분류 task는 각 token마다 classification layer가 부착되어 어떤 토큰인지 분류함.
Named Entity Recognition (NER)
- 개체명 인식은 문맥을 파악해서 인명, 기관명, 지명 등과 같은 문장 또는 문서에서 특정한 의미를 가지고 있는
단어 또는 어구(개체) 등을 인식하는 과정을 의미한다.
- 같은 단어라도 문맥에서 다양한 개체(entity)로 사용될 수 있음 => 모델이 문맥을 올바르게 파악하는 것이 중요
Part-of-speech tagging (POS TAGGING)
- 형태소 태깅 : 언어가 가지는 의미학적 최소 단위로 분류하는 것
- 개체명 인식과 마찬가지로 주어진 문맥을 파악하며 형태소 분석할 수 있음
- 품사란 단어를 문법적 성질의 공통성에 따라 언어학자들이 몇 갈래로 묶어 놓은 것이다.
- 품사 태깅은 주어진 문장의 각 성분에 대하여 가장 알맞는 품사를 태깅하는 것을 의미한다.
2) 문장 토큰 분류를 위한 데이터
kor_ner
- 한국해양대학교 자연어 처리 연구실에서 공개한 한국어 NER 데이터셋
- 일반적으로, NER 데이터셋은 pos tagging 도 함께 존재
- 개체명 태깅이 BIO로 구성됨 (Begin, Inner, Out)
- Entity tag에서 B의 의미는 개체명의 시작(Begin)을 의미하고, I의 의미는 내부(Inside)를 의미하며, O는
다루지 않는 개체명(Outside)를 의미한다.
- 즉, B-PER은 인물명 개체명의 시작을 의미하며, I-PER는 인물명 개체명의 내부 부분을 뜻한다.
- kor_ner 데이터셋에서 다루는 개체명은 다음과 같다.

4. 문장 토큰 분류 모델 학습 실습
- 주의점

형태소 단위의 토큰을 음절 단위의 토큰으로 분해하고, Entity tag 역시 음절 단위로 매핑시켜 주어야 한다.
- 학습 과정

실습
- paraphrasing된 데이터 말고 유사하지 않은 데이터를 구축할 때, 그냥 랜덤으로 선택하게 되면 의미가 정말 상반된 데이터를 가지고 학습하게 된다. 그러면 모델이 쉬운 문제를 푸는 task로 바뀌게 된다. (비슷한 문장이지만 의미가 다른 것을 구별해낼 수 없게 될 수 있다) 이를 해결하기 위해 key 값 문장과 total 문장을 BERT를 통해 sentence embedding을 하고, 가장 임베딩 결과가 유사한 문장을 선택하도록 한다.
-> 비슷한 키워드가 등장한 문장들이 유사하다고 판단된 것 확인
- BERT lingual 모델은 한국어 vocab이 8000개 정도 밖에 없고, 그 안의 한국어들의 거의 음절로 존재. -> 음절 단위 tokenizer를 적용해도 vocab id를 어느 정도 획득할 수 있음.
- 기계독해 : 질문과 답변이 포함된 문서가 주어졌을 때, 문서 토큰 내에서 정답이 어디에 위치했는지 파악하는 task
'Study > AI Tech' 카테고리의 다른 글
| Week 11 (1) MRC Intro (0) | 2021.10.12 |
|---|---|
| Week 10 (1) GPT 언어 모델 (0) | 2021.10.05 |
| Week9 (3) BERT 학습 (0) | 2021.09.29 |
| Week9 (2) BERT 언어모델 (0) | 2021.09.28 |
| Week 9 (1) 인공지능과 자연어 처리 (0) | 2021.09.27 |



